
I. What’s the modern data stack ?
The Modern Data Stack (MDS) is a fairly recent way of considering data integration and processing. Technically, it differs from the “legacy” data stack because:
- It lives on the cloud and revolves around a cloud data warehouse (often Snowflake, BigQuery or Redshift)
- Rather than being entirely made of one or two tools (ex: Talend + PostgreSQL), it is inspired from a microservice architecture and contains multiple tools/services, each specialized in one particular task. Data ingestion/integration, data transformation, discovery and orchestration will each be handled by a distinct tool
- It’s based on Python, templated SQL and YAML files
Here’s a schematic representation of the MDS (yup, there’s always tons of logos on those 😅)
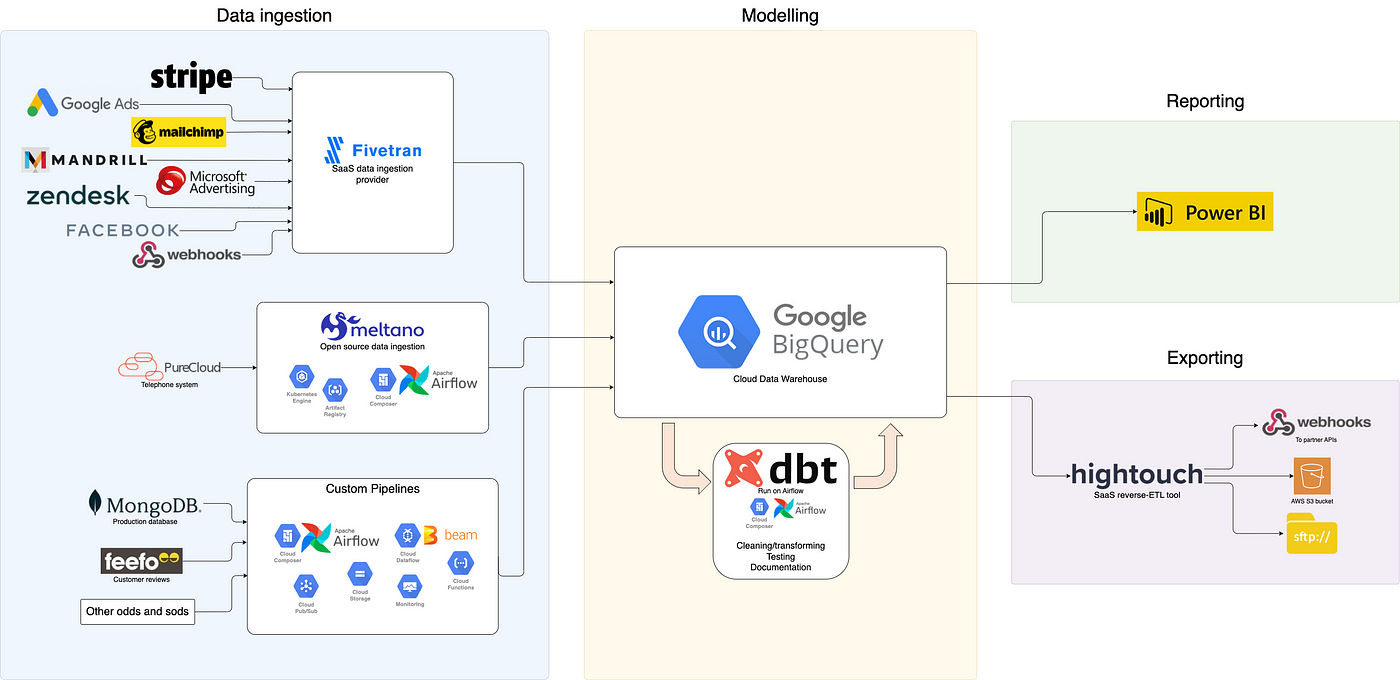
The prospects of such a stack seem cool, and there’s been a very powerful hype surrounding it, as well as tons of VC money pouring in.
II. Critics
However, some very pragmatic people in the space are telling a very different story about it. I’ve learnt through the years to listen to the few people who do not agree, when everyone else is embarked in unquestionable fear or euphoria. And indeed, those people got a few interesting points. Here’s what they say:
- The MDS is super expensive: massive cloud bills because of the ELT paradigm. Lots of raw data is stored, huge amounts of data are processed. SaaS tools like Fivetran are expensive, and data engineering talent is rare. The result here is potentially massive OPEX burn
- The MDS is technically beautiful, but it does not align with real business needs: it drives very few real-world value, is too tech-oriented and not enough value-oriented.
- The MDS is a passing VC-driven hype: VC-led tech indeed sees a new wave of massively funded startups every few years, from which only a few survive a few years later. Some would say that The MDS is defined by vendors and investors pushing tools first, and solutions around them second.
- The MDS is a total mess: Believing that it’s completely new and helps avoid all the painful stuff, companies adopt the MDS and forget to take care of governance, data modeling, data warehousing and SQL best practices, quality checks. They create very few guardrails (constraints & co), and sometimes neglect setting up proper monitoring and observability. The result is indeed messy …
- The MDS is a lots of community-led tools: companies like dbt Labs and Airbyte basically take open source community contributions from users around the world, and turn them into a SaaS product.
“The MDS provided many benefits: The Modern Data Stack solves a variety of engineering challenges relating to cost and performance. However it has regressed 30+ years when it comes to how the data is used to solve business problems." (Ben Rogojan, Speed Running The Data Infrastructure Industry)
“When it’s very easy to move data from point A to point B it can be tempting to think less about how the data represents your company’s business and focus more on building reporting that answers your current questions. Unavoidably this will likely build poorly designed schemas and data pipeline." (Ben Rogojan, Speed Running The Data Infrastructure Industry)
III. Making sense out of this
We can easily comprehend why experienced veterans feel that all the tools of the MDS are nothing new and encourage a lack of rigor or standards. The MDS makes a lot of things easy and fast. Perhaps too easy in some cases as it can be tempting to set up data pipelines and tables that haven’t gone through any form of long-term thinking. This can lead to explodind cloud costs, data swamp building, technical debt and counter-prodctive chaos.
- It’s true that new toys can seem magical at first and make us want to jump to results too fast. But this is often a mistake. Improvement happens in small increments, and the data stack is still a fast-evolving topic as no optimum was found. Everyone is trying, making mistakes and learning. There’s no free lunch ever. Data modeling, proper governance, quality gates and all that “old” stuff is still super relevant in the modern data world. These are not new concepts, but we are re-learning their relevance in this accelerated data-driven world.
- Yes, VC’s are betting big on the MDS, especially Andreessen Horowitz’s a16z. But again, that’s what they do. Invest in trends and start ups, try to get them to the IPO stage, exit with a profit. Business as usual. Also, the large influx of cash and variety of tooling has challenged a lot of norms and has taken advantage of new paradigms like the cloud.
- The monolithic and limited legacy stack surely has some flaws. The high-maintenance Hadoop cluster too. The cloud is convenient and time-saving when used wisely.
- New tech in the data space often sparks way too much enthusiasm and eagerness. That first wave of ardor generates a first generation of early adopters, who, thanks to their struggles and feed-back, give birth to a second, much better version of the technology. This can happen a few times, while the hype gradually fades to make way for a mature, robust technology. Remember when the only thing literally EVERYONE was talking about was Big Data in 2015 ? See how nobody cares anymore ? I worked with Spark 1.5 circa 2015, and I can assure you that the latest versions have gotten MUCH MUCH better.
- I still think, because I witnessed it, that the MDS is great, and can bring lots of value, but that is true under certain conditions:
- Do not try to discard older, established, battle-tested principles. There is a reason they survived for 40 years and are still taught at college.
- Try to think about 2nd and 3rd order consequences of your choices. Simulate estimates of your cloud bill 5 years from now, think about durability (will this still be relevant 5 years from now?).
- Do not attempt to migrate into the MDS if you do not have great DevOps, Data Engineering, Data Architecture and overall Software Engineering skills in-house. Efficiently managing Airflow in production ain’t simple.
- The hype is already fading, especially with cash getting more and more expensive in the US. We are now reaching the reasonable moment, great progress will happen, bad tools and companies will disappear, standards will settle and get widely adopted, creating more vibrant communities and even more progress.
- FinOps will finally make a serious entry into the data world, and help control cloud costs better.
Overall, I don’t believe there’s fundamentally good or bad new tech. Let’s just keep a critical and curious mind and see what good there is to take from this particular trend, and from all the others.
Here’s a representation of the textbook MDS, VS a more “reasonable” and balanced stack (called Postmodern data stack by the author of this, Lauren Balik):
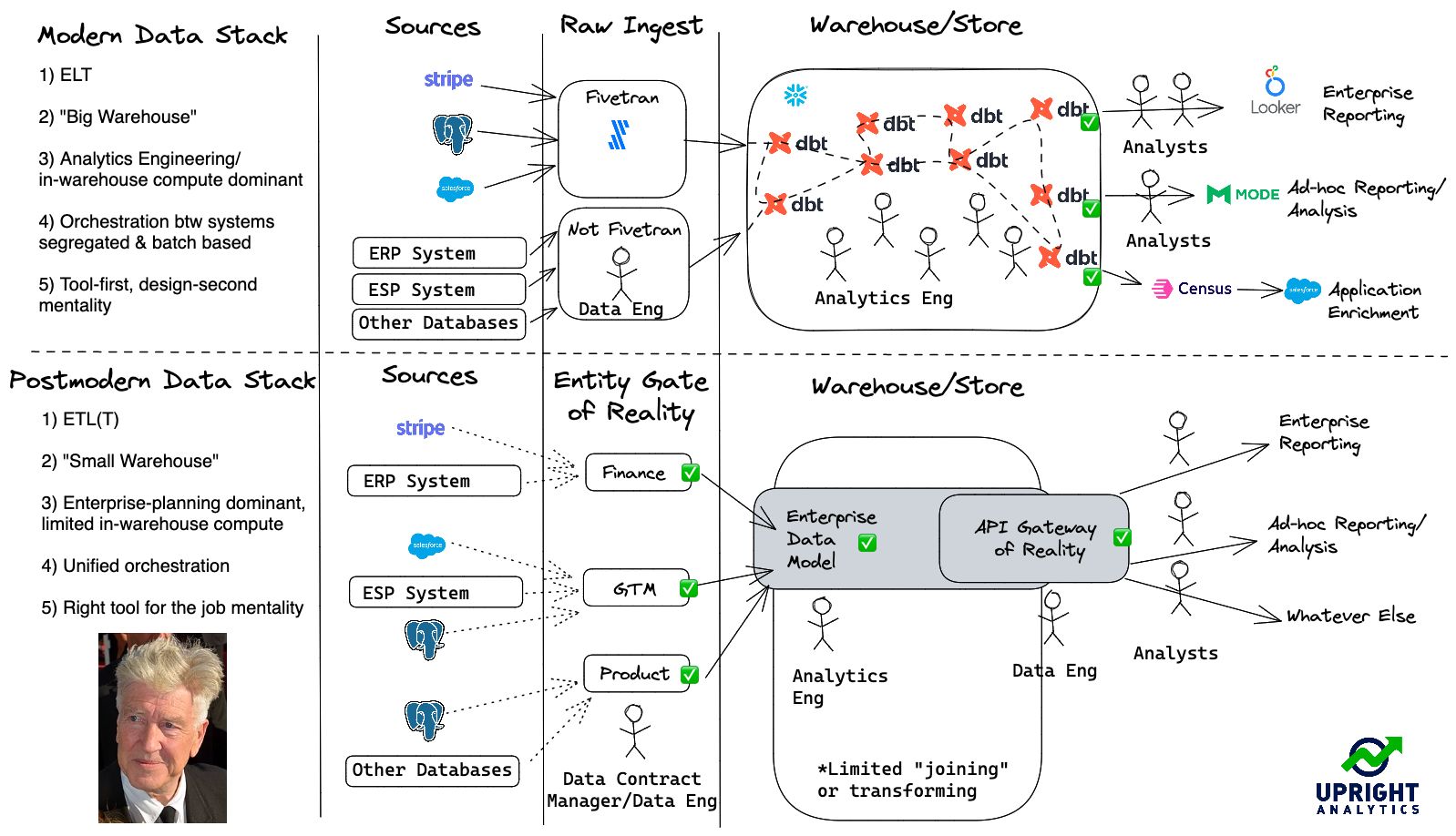
Thanks for reading ! 😊👋
Anas EL KHALOUI